

陈龙:ChatGPT两周年,美国科技公司“AI 七姐妹”: 领跑者的七个启示(第一篇)
时间:24-12-02 来源:为溪进化派
陈龙:ChatGPT两周年,美国科技公司“AI 七姐妹”:
领跑者的七个启示(第一篇)
引言
自2022年11月ChatGPT聊天机器人推出以来,短短两个月内用户规模就突破了一亿大关,创下了消费级应用用户增长速度的新纪录。这标志着人类迈入了人工智能革命的新纪元。
如今,两年的时间已经过去。
越来越多的人开始认识到,这场革命可能是一个千载难逢的机遇,其影响力堪比电力革命,对经济和商业都将产生深远的影响。最近,我与罗汉堂学术委员会成员、复杂经济学奠基人、《技术的本质》(这是关于科技最经典的书籍之一)的作者Brian Arthur教授进行了深入交流。他相信,这场AI革命的潜力或可与14世纪印刷术对人类社会的影响相媲美:“如果我们在2100年回顾21世纪,可能会认为,70多年前发生的最重要的事件不是地缘政治或战争,而是AI技术的突破”。
技术要融入经济体系,商业应用是其载体。因此,在技术领先于应用的时期,正是商业领域最充满激情的阶段。那么,如果有一个可比电力革命的机会,我们应该如何带着对电力革命的理解,去拥抱这次机会?
像往次科技革命一样,人们带着热望和焦虑,围绕AI争辩几类经典商业问题:
第一,技术革命的本质:此次AI技术突破能走多远?
第二,改变商业的路径:它会先影响哪些产业,以及对哪些产业影响更大?
第三,技术和商业的关系:它对现有的商业是无情的颠覆者,还是伟大的赋能者?它是少数玩家的游戏,还是很多人的机遇?
第四,拥抱技术的方式:对于抓住这次机遇,有哪些值得借鉴的经验和教训?
美国科技公司“AI 七姐妹”:领跑者的七个启示
美国前七位的科技公司,包括微软、英伟达、苹果、谷歌、亚马逊、脸谱和特斯拉,也被称为“AI七姐妹”。它们既包括了最先进的算力领导者,最前沿的大模型,也包括了数字化成熟度最高、数据最丰富的应用场景,同时因为其海量用户,是最重要的新AI技术的普及推广者。可以说,这七家企业是当下全球AI商业最重要的引领者与代表者。

因此,七姐妹的AI实践和效果,可以给我们带来很多启示,从而理解本次AI革命日渐清晰的一些确定性趋势。
在这篇系列文章中,我将以“AI七姐妹”为研究对象,把已经表现出来的商业特征总结成七个启示:
第一,单一还是多元:智能的本质决定了大模型不会赢家通吃。一个多元、多层(包括通用大模型、产业大模型、专业大模型的不同组合)、多玩家的产业生态格局正在全球形成。
第二,赋能还是颠覆:AI对于没有丰富数据场景的产业,影响不大;而对于有丰富数据场景的产业,在现阶段是伟大的赋能者,而非颠覆。
第三,战略还是工具:AI对于有的企业是减肥增肌,而对有的企业,已经起到了战略升级和重构的显著效果。这是一个如何拥抱AI革命的关键问题。其差别除了和行业本质有关,也取决于企业的认知力、决策力、执行力。
第四,闭环还是开放:Meta的AI开源生态战略,是2023年在AI商业领域最重要的事件,也代表了开放协同、而非自闭环,是AI商业发展最重要的方向。
第五,铲子还是挖矿:AI基础设施的建设者,即“铲子”,成为早期最大的受益者,但大部分AI红利会逐渐转移到应用端,即挖矿者。
第六,技术还是商业:科技的成功不等于商业的成功。技术的优势短暂易逝,商业的持续成功取决于是否能构建融合技术和商业的护城河。
第七,中心化还是去中心化:企业可以前所未有的大,创业者也是前所未有的多。这是大企业的时代,也是所有人的游戏。数字革命从互联网走入AI,对商业的根本影响在进入一个新的阶段。
这七个启示,前两个有关AI的技术本质所定义的经济和商业游戏规则,后五个则是商业拥抱AI的方式和效果。所谓启示,指的是事先答案未明、事后能予人顿悟的认知。
第一个启示:单一还是多元?

01
大模型会是多少玩家的机会?
一个最让人关心的话题是,AI技术会以何种方式改变商业格局?大模型会是多少玩家的机会?
几个因素的结合,让人们产生了大模型企业会几家独大,甚至赢者通吃、催生超级App的早期判断。首先是ChatGPT面世以后,在从零到一阶段没有竞争对手,犹如明月独悬,很容易让人产生一骑绝尘的印象。其次,每一次GPT升级,都会淘汰上千个中间层功能,表现了强大的通用学习替代能力。
于是就产生了这样的观点:从逻辑上看,更多的数据→更先进的模型→更好的产品→更多用户→更多数据。机器智能和大数据以及应用场景的结合,会放大大模型的网络效应和规模回报。同样重要的是,和以往不同,机器智能是一种学习型技术,能够从数据中学习知识和逻辑,沉淀到神经网络中,从而脱离对已经学习过的数据的依赖。这样大模型会越来越聪明和有主导力,形成一种智能黑洞,甚至不需要中间层的协同。如果大模型和大数据能够形成正向飞轮,并且攫取数据的价值,这两个特征若同时成立,则意味着大模型会越来越集中,越来越有价值,甚至形成大模型主导的超级APP。
不少实践者认同这个观点。例如,百度创始人李彦宏认为,目前“百模大战”是在浪费社会资源,两三个大模型就足够了,同时会逐步出现三五个超级应用,以及数以百万计、甚至千万计的各种应用。OpenAI创始人萨姆·阿尔特曼(Sam Altman)也认为,很多创业公司不应该浪费资源发展中间层,最终可能更多是调用API的模式。大模型的势能是如此之大,以至于原微软全球执行副总裁陆奇在2023年指出,“OpenAI肯定会比谷歌大,只是大多少倍的问题”。
事实上,大模型从问世以来的技术爆发初级阶段,其发展的核心趋势和以上判断相差甚远。
首先在基础大模型层面,美国有多家并行发展,且在核心能力上没有代差。OpenAI的GPT在引领本轮AI从零到一的突破之后,很快遇到各种出身不同的强有力的追赶者。无论大科技公司谷歌基于多模态数据开发的Gemini,OpenAI之外另一个创业公司Anthropic的Claude,马斯克创立的xAI所开发的Grok-2,甚至Meta的开源模型Llama,其表现和GPT相比都不逊色。图1为大模型不同测评项目中,提到的5家大模型得分对比,可以看到,没有一个模型具有显著优势。
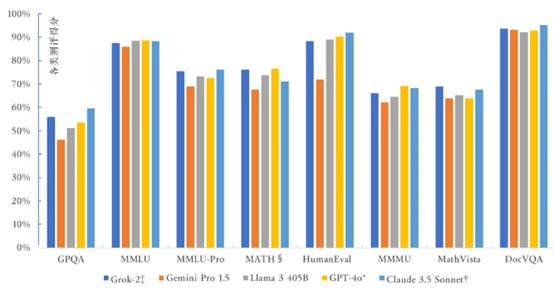
图1:美国头部大模型测评得分对比,上述各项指标包括GPQA(理科博士难题)、MMLU(大规模多任务语言理解)、MMLU-Pro(MMLU优化版)、MATH§(数学问题)、HumanEval(编程能力)、MMMU(大学学科知识水平)、MathVista(多模态数学问题)、DocVQA(文档视觉问答) 。Gemini 1.5 Pro 的分数发布于2024年4月,GPT-4o 的分数发布于2024年5月;Claude 3.5 Sonnet 分数发布于2024年6月;Llama 3 的分数发布于2024年7月;Grok-2 的分数发布于2024年8月。
鉴于模型能力拉不开代差,如图2所示,国内外大模型企业,以OpenAI和通义千问为例,从2023年已经开始了激烈的价格战,旗舰大模型价格下降了90%以上。同时,为进一步压低推理应用的价格,各模型厂商推出的以效率为主的小模型,token价格又不及旗舰大模型的1/10,openAI-4o-mini 价格为0.24美元/百万Token, 通义千问的Qwen2.5-Turbo 更是低至0.3元人民币/百万token。
当下各种大模型拉不开差距的竞争,不但与赢家通吃的预想相差甚远,而且已经改变了大模型企业的现金流能力和发展路径。未来,大模型的方向有何可能?原则上,大模型未来的发展方向要么需要有足够大的规模能够承接低利润的模式;要么能够很快转化成应用收入;要么能够给出实现类似目标的清晰路径,从而获得融资。竞争足够激烈,对现金流的确定性就提出了很大的要求。

图2:国内外大模型近1年持续降价情况;国外以OpenAI,国内以通义千问为例。
02
产业大模型与专业大模型的涌现
除了基础大模型,还有很多产业大模型和专业大模型在不断产生。尤其重要的是,这些大模型追求的不是最先进的通用智能,而是能够在现实的产业场景中实现价值创造,也就是追求大模型和大数据结合的转化效率。
比如参数的最大化不再是绝大部分大模型的追求目标,这是因为参数越大,调用效率就越低;最好的大模型,实际上是在有限的参数下更加有效地解决现实中的问题。这对大部分企业意味着,企业需要关心的问题不是什么是最先进的大模型,而是什么大模型能够最有效地带来商业价值。如图3所示,新一代的小模型表现优异,虽不优于最新大模型版本,但已经比上一版本的大模型更加优秀。
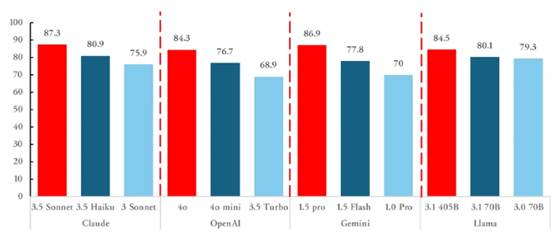
图3:模型厂商推出新一代通用大模型时,会同时发布性价比高的小模型版本。今年5月发布的Gemini 1.5 Flash 是Gemini高速响应的小模型版本,表现优于Gemini 1.0大模型;7月发布的GPT-4o mini 全面碾压上一代模型 GPT-3.5 Turbo;Llama 3.1 则是在7月推出405B的大模型同时,发布了70B、8B参数的小模型版本,性能全面优于4月推出的Llama 3.0版本;10月更新的Claude 3.5 Haiku小模型表现已经优于3月推出的 Claude 3 Sonnet 大模型。
实际上,这些小模型搭配具体的应用场景和数据,在特定任务上的表现不弱于通用旗舰大模型。如图4,利用产业内专业数据训练的小模型在特定产业内的能力测评已经超越GPT4通用模型。
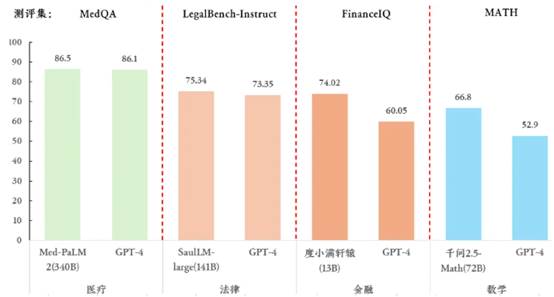
图4:医疗领域,谷歌的Med-PaLM2利用大量医疗专业数据训练,在23年4月发布的测评结果中优于当时最强大模型GPT4-base;法律领域,24年7月发布的法律垂直模型SaulLM,使用5400亿 token 专业法律数据训练,表现优于GPT-4; 金融领域,轩辕3.0在24年9月金融场景任务的测评中,超越GPT-4o;数学领域,24年9月发布的Qwen2.5-Math 通过更高质量的数学数据训练,在多项数学测试中优于GPT-4o。
可见,由大量专业数据训练出的产业小模型,虽然参数只在13B 到340B 之间,与GPT-4的1800B(据称)相差甚远,但在不同专业领域的表现都各自超过GPT-4。
其次,不是追求大模型的大、而是大模型结合数据应用的有效性,这个趋势正在很多国家发生。现在美国、中国、欧洲是主要的AI大模型研发区域,大部分以追求实际价值为目标,而非大模型军备竞赛。比如法国的Mistral AI,通过有限程度开源,以相对小的参数量(1230亿)追求普及效果。德国的大模型企业代表Aleph Alpha,定位是德国自己的“Open AI”,开发的大模型Luminous包括130亿、300亿和700亿三种参数。并针对欧洲各国语言习惯和欧盟法规,推出了针对性的Pharia-1-LLM语言模型,虽然只有70亿参数,但专业化的训练使得其满足企业、政府的需求。
被谷歌收购、但代表英国AI发展水平的DeepMind,其代表产品是Alpha专业大模型系列,如AlphaGo围棋机器人,AlphaFold蛋白质预测模型,AlphaCode代码生成工具。还有全球研究人员合作研发的通用大模型,例如由BigScience发布的BLOOM系列模型。这些模型都不是以参数大,而是以专业能力为特征。
所以,虽然Open AI仍然是风向标,但在过去两年中,一个多元、多层(包括芯片、云计算、通用大模型、产业大模型、专业大模型的不同组合)、多玩家的AI产业生态正在全球形成。这个生态最核心的发展目标,是以实际的需求和价值实现为引擎,来推动大模型的技术迭代。这个多玩家生态,意味着个别的通用大模型不会主导产业格局,也没有形成超级APP的趋势。
当然,大模型技术本身还在快速演化中。一个重要的趋势,是从原来注重通过“大力出奇迹”,训练出来的相对简单的推理能力,到更加注重在实际推理应用阶段,能够延长推理时间,构建思维链和决策链,从而可以解决相对复杂的推理问题。比如Open AI最新的O1模型,其核心进步,就是学会延长实际应用时的推理时间,这已经在科学等领域带来显著效果。
这个转变非常类似心理学家丹尼尔·卡尼曼(2002年获得诺贝尔经济学奖)在其名著《快思考,慢思考》中说描述的人类的两种思维方式,即在生活中大量像条件反射式的“快思考”(浅推理能力),以及应对复杂问题时所需要的“慢思考”(复杂推理能力)。大模型技术在探索复杂推理能力,也就更加符合人类的思维模式。机器智能与人类智能,虽然发展路径不同,但最基本的规律,两者都绕不过去。
但这个从快思考到慢思考的大模型技术演变,并没有改变前速趋势。第一,因为各种大模型都会做类似的尝试,没有迹象表明哪一家企业可以绝对拉开代差。第二,注重复杂思维和决策能力,会更加需要高质量的产业数据和知识技能(know-how)。所以前述的几个主要趋势,不会因为大模型技术的演化而逆转,反而会强化产业和专业大模型的优势。
03
智能的本质是什么?何以智能?
AI革命以来,这些正在发生的趋势,帮我们更好地理解了什么是智能,以及智能迭代的最佳路径。
智能在本质上可以被理解为“推理?信息?应用”,在这个时代就是“大模型?大数据?应用”。AI就像不同聪明程度的人一样,本质上是一种信息处理技术(information processing technology),即通过对信息的处理,在应用中实现价值。这意味着智能的获取和迭代包含了推理能力、信息质量、应用效果三个环节。
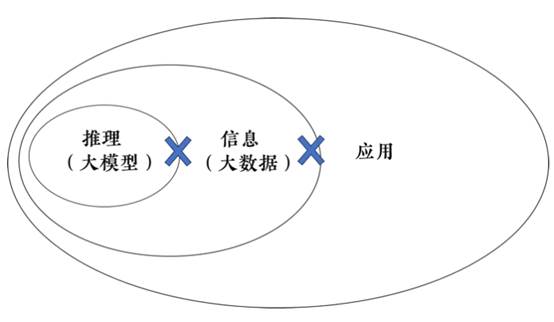
图5:通过推理?信息?应用实现推理能力对现实应用场景的赋能。

基于这个本质,智能的进化有两种可能性:一种是大模型主导数据和应用的越来越快的正循环,形成“AI?数据的黑洞”,其结局就是强者恒强,甚至赢家通吃。在很多年以前,类似的“数据黑洞”的说法就已经存在)。第二种可能性,则是AI技术方、数据方和应用场景方没有一方绝对主导,最终呈现的是多方参与的丰富生态。过去两年表明,数据质量被限制在公共数据领域的大模型,可以具备一定的通用分析能力,但并不是深入懂产业或者应用场景的专家,这决定了第二种可能性是智能迭代的发展路径。
一方面,这意味着AI产业格局未来的发展,是模型方、数据方、业务方协同的方式,而非大模型主导,这实际上定义了AI产业的多玩家格局和发展方向;另一方面,因为大模型、数据、应用组合和进化的不同,未来存在不同维度、不同层次,以及产业化、个性化的智能。
对于众多产业和创业者来说,这无疑是一个好消息。由于成功不仅仅依赖于技术本身,还需要其他关键因素的配合,这表明在AI领域, AI的商业设计可能比技术本身更为关键。
总结
AI产业的未来
在这里,我们总结一下这个启示的几个有价值的思考和观点:
第一,自大模型问世到快速发展的的两年中,从Open AI一家独秀,已经发展出几个明显的趋势:
1.通用大模型之间,无论源自大科技公司还是创业公司,在效果上拉不开代差,竞争激烈。
2.因为激励竞争,大模型以及推理价格都急剧下降。
3.大模型中的小模型,搭配具体的应用场景和数据,在特定任务上的表现不输通用旗舰大模型,而且成本更加有竞争力。
4.在当前的人工智能领域,除了基础大模型之外,产业大模型和专业大模型正逐渐成为推动行业进步的关键力量。这些模型的目标并非追求最前沿的通用智能,而是专注于在实际产业环境中创造价值。它们追求的是大模型与大数据结合的效率,即如何将大模型的潜力与实际数据有效结合起来,以实现价值有效转化,这种趋势在全球范围内正在兴起。
5.目前,全球范围内正在构建一个多元化、多层次的产业生态体系,其中涵盖了通用大模型、行业大模型以及专业大模型的多样化组合。在这个生态系统中,多个参与者共同推动着行业的发展。并没有迹象显示某个单一的大模型能够独占鳌头,同样,也没有迹象表明会基于这些大模型发展出垄断市场的超级应用APP。
6.大模型技术本身正在快速演化,从注重预训练的快思考,到注重应用阶段的慢思考,从而提升复杂推理能力。但前述的几个主要趋势,不会因为大模型技术的演化而逆转,反而会强化产业和专业大模型的优势。
第二,这些趋势可以帮我们更好理解智能的本质。智能本质上是一种数据处理技术(information processing technology),即通过对数据的处理,在应用中实现价值;这样,智能的三个环节:“推理?信息?应用”,都很重要。这意味着智能的迭代有两种可能性。一种是推理能力主导数据和应用场景,形成AI黑洞,甚至赢家通吃。另外一种可能性是推理能力、数据资产和应用场景是相互协同并存的关系。第二种可能性被证明更接近现实。
第三,一方面,这意味着这是一个多玩家的产业格局,和互联网时代非常不一样。另一方面,这也意味着每个产业、每个企业、甚至每个人,未来都可能拥有属于自己的大模型。
未来,AI产业会呈现什么样的格局?大概率未来的发展不会是一个包打天下的天才,而是有很多很多更加聪明的专家,这是AI产业的未来。
摘自-为溪进化派
| 上一篇 | 下一篇 |
|---|---|
| 伟大投资的三个特点 | 伟大的平凡,巴菲特2025致股东信 |
